


















































 Islands")


















































")






")
















































")
























































































")
")





 Germany
Germany
 Japan
Japan
 United Kingdom
United Kingdom
 China
China
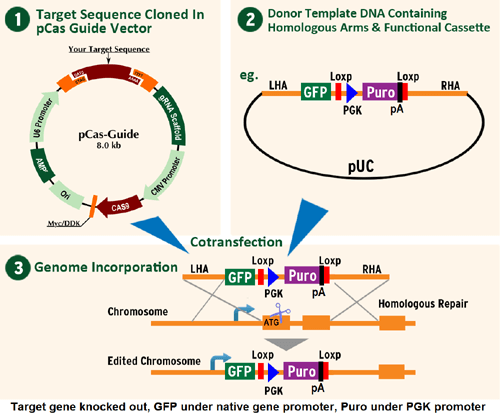
Carbonic Anhydrase IX (CA9) Human Gene Knockout Kit (CRISPR)
CAT#: KN204839
CA9 - human gene knockout kit via CRISPR, HDR mediated
Functional Cassette: Luciferase-Puro RFP-BSD mBFP-Neo
HDR-mediated knockout kit validation
USD 1,657.00
2 Weeks*
Product Images
Specifications
| Product Data | |
| Format | 2 gRNA vectors, 1 GFP-puro donor, 1 scramble control |
| Donor DNA | GFP-puro |
| Symbol | Carbonic Anhydrase IX |
| Locus ID | 768 |
| Components |
KN204839G1, Carbonic Anhydrase IX gRNA vector 1 in pCas-Guide CRISPR vector, Target Sequence: CTGGCTCCCTCTGTTGATCC KN204839G2, Carbonic Anhydrase IX gRNA vector 2 in pCas-Guide CRISPR vector, Target Sequence: AGCAGTTGCACAGTGAGGCC KN204839D, donor DNA containing left and right homologous arms and GFP-puro functional cassette. Homologous arm and GFP-puro sequences: pUC vector backbone in gray; Left arm sequence in blue; GFP-puro in green; Right arm in violet GATCGTTGGG AACCGGAGCT GAATGAAGCC ATACCAAACG ACGAGCGTGA CACCACGATG CCTGTAGCAA TGGCAACAAC GTTGCGCAAA CTATTAACTG GCGAACTACT TACTCTAGCT TCCCGGCAAC AATTAATAGA CTGGATGGAG GCGGATAAAG TTGCAGGACC ACTTCTGCGC TCGGCCCTTC CGGCTGGCTG GTTTATTGCT GATAAATCTG GAGCCGGTGA GCGTGGTTCT CGCGGTATCA TTGCAGCACT GGGGCCAGAT GGTAAGCCCT CCCGTATCGT AGTTATCTAC ACGACGGGGA GTCAGGCAAC TATGGATGAA CGAAATAGAC AGATCGCTGA GATAGGTGCC TCACTGATTA AGCATTGGTA ACTGTCAGAC CAAGTTTACT CATATATACT TTAGATTGAT TTAAAACTTC ATTTTTAATT TAAAAGGATC TAGGTGAAGA TCCTTTTTGA TAATCTCATG ACCAAAATCC CTTAACGTGA GTTTTCGTTC CACTGAGCGT CAGACCCCGT AGAAAAGATC AAAGGATCTT CTTGAGATCC TTTTTTTCTG CGCGTAATCT GCTGCTTGCA AACAAAAAAA CCACCGCTAC CAGCGGTGGT TTGTTTGCCG GATCAAGAGC TACCAACTCT TTTTCCGAAG GTAACTGGCT TCAGCAGAGC GCAGATACCA AATACTGTTC TTCTAGTGTA GCCGTAGTTA GGCCACCACT TCAAGAACTC TGTAGCACCG CCTACATACC TCGCTCTGCT AATCCTGTTA CCAGTGGCTG CTGCCAGTGG CGATAAGTCG TGTCTTACCG GGTTGGACTC AAGACGATAG TTACCGGATA AGGCGCAGCG GTCGGGCTGA ACGGGGGGTT CGTGCACACA GCCCAGCTTG GAGCGAACGA CCTACACCGA ACTGAGATAC CTACAGCGTG AGCTATGAGA AAGCGCCACG CTTCCCGAAG GGAGAAAGGC GGACAGGTAT CCGGTAAGCG GCAGGGTCGG AACAGGAGAG CGCACGAGGG AGCTTCCAGG GGGAAACGCC TGGTATCTTT ATAGTCCTGT CGGGTTTCGC CACCTCTGAC TTGAGCGTCG ATTTTTGTGA TGCTCGTCAG GGGGGCGGAG CCTATGGAAA AACGCCAGCA ACGCGGCCTT TTTACGGTTC CTGGCCTTTT GCTGGCCTTT TGCTCACATG TTCTTTCCTG CGTTATCCCC TGATTCTGTG GATAACCGTA TTACCGCCTT TGAGTGAGCT GATACCGCTC GCCGCAGCCG AACGACCGAG CGCAGCGAGT CAGTGAGCGA GGAAGCGGAA GAGCGCCCAA TACGCAAACC GCCTCTCCCC GCGCGTTGGC CGATTCATTA ATGCAGCTGG CACGACAGGT TTCCCGACTG GAAAGCGGGC AGTGAGCGCA ACGCAATTAA TGTGAGTTAG CTCACTCATT AGGCACCCCA GGCTTTACAC TTTATGCTTC CGGCTCGTAT GTTGTGTGGA ATTGTGAGCG GATAACAATT TCACACAGGA AACAGCTATG ACCATGATTA CGCCAAGCTC CTTCCTCTTC CAGCCCTTCC TCTTTCACTG ACTGACTGAC TGGAAGACAC ACCTTGTTGA AAAATAAATA TAGGTTAAAC CTATCAGAGC CCCTCTGACA CATACACTTG CTTTTCATTC AAGCTCAAGT TTGTCTCCCA CATACCCATT ACTTAACTCA CCCTCGGGCT CCCCTAGCAG CCTGCCCTAC CTCTTTACCT GCTTCCTGGT GGAGTCAGGG ATGTATACAT GAGCTGCTTT CCCTCTCAGC CAGAGGACAT GGGGGCCCCA GCTCCCCTGC CTTTCCCCTT CTGTGCCTGG AGCTGGGAAG CAGGCCAGGG TTAGCTGAGG CTGGCTGGCA AGCAGCTGGG TGGTGCCAGG GAGAGCCTGC ATAGTGCCAG GTGGTGCCTT GGGTTCCAAG CTGAGTCCAT GGCCCCGATA ACCTTCTGCC TGTGCACACA CCTGCCCCTC ACTCCACCCC CATCCTAGCT TTGGTATGGG GGAGAGGGCA CAGGGCCAGA CAAACCTGTG AGACTTTGGC TCCATCTCTG CAAAAGGGCG CTCTGTGAGT CAGCCTGCTC CCCTCCAGGC TTGCTCCTCC CCCACCCAGC TCTCGTTTCC AATGCACGTA CAGCCCGTAC ACACCGTGTG CTGGGACACC CCACAGTCAG CCGCACTAGC ATGGAGAGCG ACGAGAGCGG CCTGCCCGCC ATGGAGATCG AGTGCCGCAT CACCGGCACC CTGAACGGCG TGGAGTTCGA GCTGGTGGGC GGCGGAGAGG GCACCCCCGA GCAGGGCCGC ATGACCAACA AGATGAAGAG CACCAAAGGC GCCCTGACCT TCAGCCCCTA CCTGCTGAGC CACGTGATGG GCTACGGCTT CTACCACTTC GGCACCTACC CCAGCGGCTA CGAGAACCCC TTCCTGCACG CCATCAACAA CGGCGGCTAC ACCAACACCC GCATCGAGAA GTACGAGGAC GGCGGCGTGC TGCACGTGAG CTTCAGCTAC CGCTACGAGG CCGGCCGCGT GATCGGCGAC TTCAAGGTGA TGGGCACCGG CTTCCCCGAG GACAGCGTGA TCTTCACCGA CAAGATCATC CGCAGCAACG CCACCGTGGA GCACCTGCAC CCCATGGGCG ATAACGATCT GGATGGCAGC TTCACCCGCA CCTTCAGCCT GCGCGACGGC GGCTACTACA GCTCCGTGGT GGACAGCCAC ATGCACTTCA AGAGCGCCAT CCACCCCAGC ATCCTGCAGA ACGGGGGCCC CATGTTCGCC TTCCGCCGCG TGGAGGAGGA TCACAGCAAC ACCGAGCTGG GCATCGTGGA GTACCAGCAC GCCTTCAAGA CCCCGGATGC AGATGCCGGT GAAGAAAGAG TTTAAGAATT CCGATCATAT TCAATAACCC TTAATATAAC TTCGTATAAT GTATGCTATA CGAAGTTATT AGGTCTGAAG AGGAGTTTAC GTCCAGCCAA GCTTAGGATC TCGACCTCGA AATTCTACCG GGTAGGGGAG GCGCTTTTCC CAAGGCAGTC TGGAGCATGC GCTTTAGCAG CCCCGCTGGG CACTTGGCGC TACACAAGTG GCCTCTGGCC TCGCACACAT TCCACATCCA CCGGTAGGCG CCAACCGACT CCGTTCTTTG GTGGCCCCTT CGCGCCACCT TCTACTCCTC CCCTAGTCAG GAAGTTCCCC CCCGCCCCGC AGCTCGCGTC GTGCAGGACG TGACAAATGG AAGTAGCACG TCTCACTAGT CTCGTGCAGA TGGACAGCAC CGCTGAGCAA TGGAAGCGGG TAGGCCTTTG GGGCAGCGGC CAATAGCAGC TTTGCTCCTT CGCTTTCTGG GCTCAGAGGC TGGGAAGGGG TGGGTCCGGG GGCGGGCTCA GGGGCGGGCT CAGGGGCGGG GCGGGCGCCC GAAGGTCCTC CGGAGGCCCG GCATTCTGCA CGCTTCAAAA GCGCACGTCT GCCGCGCTGT TCTCCTCTTC CTCATCTCCG GGCCTTTCGA CCTGCATCCA TCTAGATCTC GAGCAGCTGA AGCTTACCAT GACCGAGTAC AAGCCCACGG TGCGCCTCGC CACCCGCGAC GACGTCCCCA GGGCCGTACG CACCCTCGCC GCCGCGTTCG CCGACTACCC CGCCACGCGC CACACCGTCG ATCCGGACCG CCACATCGAG CGGGTCACCG AGCTGCAAGA ACTCTTCCTC ACGCGCGTCG GGCTCGACAT CGGCAAGGTG TGGGTCGCGG ACGACGGCGC CGCGGTGGCG GTCTGGACCA CGCCGGAGAG CGTCGAAGCG GGGGCGGTGT TCGCCGAGAT CGGCCCGCGC ATGGCCGAGT TGAGCGGTTC CCGGCTGGCC GCGCAGCAAC AGATGGAAGG CCTCCTGGCG CCGCACCGGC CCAAGGAGCC CGCGTGGTTC CTGGCCACCG TCGGCGTCTC GCCCGACCAC CAGGGCAAGG GTCTGGGCAG CGCCGTCGTG CTCCCCGGAG TGGAGGCGGC CGAGCGCGCC GGGGTGCCCG CCTTCCTGGA GACCTCCGCG CCCCACAACC TCCCCTTCTA CGAGCGGCTC GGCTTCACCG TCACCGCCGA CGTCGAGGTG CCCGAAGGAC CGCGCACCTG GTGCATGACC CGCAAGCCCG GTGCCTGACG CCCGCCCCAC GACCCGCAGC GCCCGACCGA AAGGAGCGCA CGACCCCATG CATCGATGAT ATCAGATCCC CGGGATGCAG AAATTGATGA TCTATTAAAC AATAAAGATG TCCACTAAAA TGGAAGTTTT TCCTGTCATA CTTTGTTAAG AAGGGTGAGA ACAGAGTACC TACATTTTGA ATGGAAGGAT TGGAGCTACG GGGGTGGGGG TGGGGTGGGA TTAGATAAAT GCCTGCTCTT TACTGAAGGC TCTTTACTAT TGCTTTATGA TAATGTTTCA TAGTTGGATA TCATAATTTA AACAAGCAAA ACCAAATTAA GGGCCAGCTC ATTCCTCCCA CTCATGATCT ATAGATCTAT AGATCTCTCG TGGGATCATT GTTTTTCTCT TGATTCCCAC TTTGTGGTTC TAAGTACTGT GGTTTCCAAA TGTGTCAGTT TCATAGCCTG AAGAACGAGA TCAGCAGCCT CTGTTCCACA TACACTTCAT TCTCAGTATT GTTTTGCCAA GTTCTAATTC CATCAGAAGC TGGTCGAGAT CCGGAACCCT TAATATAACT TCGTATAATG TATGCTATAC GAAGTTATTA GGTCCCTCGA AGAGGTTCAC TAGGCGCGCC ACTGCTGCTT CTGGTGCCTG TCCATCCCCA GAGGTTGCCC CGGATGCAGG AGGATTCCCC CTTGGGAGGA GGCTCTTCTG GGGAAGATGA CCCACTGGGC GAGGAGGATC TGCCCAGTGA AGAGGATTCA CCCAGAGAGG AGGATCCACC CGGAGAGGAG GATCTACCTG GAGAGGAGGA TCTACCTGGA GAGGAGGATC TACCTGAAGT TAAGCCTAAA TCAGAAGAAG AGGGCTCCCT GAAGTTAGAG GATCTACCTA CTGTTGAGGC TCCTGGAGAT CCTCAAGAAC CCCAGAATAA TGCCCACAGG GACAAAGAAG GTAAGTGGTC ATCAATCTCC AAATCCAGGT TCCAGGAGGT TCATGACTCC CCTCCCATAC CCCAGCCTAG GCTCTGTTCA CTCAGGGAAG GAGGGGAGAC TGTACTCCCC ACAGAAGCCC TTCCAGAGGT CCCATACCAA TATCCCCATC CCCACTCTCG GAGGTAGAAA GGGACAGATG TGGAGAGAAA ATAAAAAGGG TGCAAAAGGA GAGAGGTGAG CTGGATGAGA TGGGAGAGAA GGGGGAGGCT GGAGAAGAGA AAGGGATGAG AACTGCAGAT CATCCAGTCT TCACTGACTG ACTGACTGGA AAGTCCTCTC CACTGACTGT AGCCTCCAAT TCACTGGCCG TCGTTTTACA ACGTCGTGAC TGGGAAAACC CTGGCGTTAC CCAACTTAAT CGCCTTGCAG CACATCCCCC TTTCGCCAGC TGGCGTAATA GCGAAGAGGC CCGCACCGAT CGCCCTTCCC AACAGTTGCG CAGCCTGAAT GGCGAATGGC GCCTGATGCG GTATTTTCTC CTTACGCATC TGTGCGGTAT TTCACACCGC ATACGTCAAA GCAACCATAG TACGCGCCCT GTAGCGGCGC ATTAAGCGCG GCGGGTGTGG TGGTTACGCG CAGCGTGACC GCTACACTTG CCAGCGCCCT AGCGCCCGCT CCTTTCGCTT TCTTCCCTTC CTTTCTCGCC ACGTTCGCCG GCTTTCCCCG TCAAGCTCTA AATCGGGGGC TCCCTTTAGG GTTCCGATTT AGTGCTTTAC GGCACCTCGA CCCCAAAAAA CTTGATTTGG GTGATGGTTC ACGTAGTGGG CCATCGCCCT GATAGACGGT TTTTCGCCCT TTGACGTTGG AGTCCACGTT CTTTAATAGT GGACTCTTGT TCCAAACTGG AACAACACTC AACCCTATCT CGGGCTATTC TTTTGATTTA TAAGGGATTT TGCCGATTTC GGCCTATTGG TTAAAAAATG AGCTGATTTA ACAAAAATTT AACGCGAATT TTAACAAAAT ATTAACGTTT ACAATTTTAT GGTGCACTCT CAGTACAATC TGCTCTGATG CCGCATAGTT AAGCCAGCCC CGACACCCGC CAACACCCGC TGACGCGCCC TGACGGGCTT GTCTGCTCCC GGCATCCGCT TACAGACAAG CTGTGACCGT CAACGGGAGC TGCATGTGTC AGAGGTTTTC ACCGTCATCA CCGAAACGCG CGACCCGAAA GGGCCTCGTG ATACGCCTAT TTTTATAGGT TAATGTCATG ATAATAATGG TTTCTTAGAC GTCAGGTGGC ACTTTTCGGG GAAATGTGCG CGGAACCCCT ATTTGTTTAT TTTTCTAAAT ACATTCAAAT ATGTATCCGC TCATGAGACA ATAACCCTGA TAAATGCTTC AATAATATTG AAAAAGGAAG AGTATGAGTA TTCAACATTT CCGTGTCGCC CTTATTCCCT TTTTTGCGGC ATTTTGCCTT CCTGTTTTTG CTCACCCAGA AACGCTGGTG AAAGTAAAAG ATGCTGAAGA TCAGTTGGGT GCACGAGTGG GTTACATCGA ACTGGATCTC AACAGCGGTA AGATCCTTGA GAGTTTTCGC CCCGAAGAAC GTTTTCCAAT GATGAGCACT TTTAAAGTTC TGCTATGTGG CGCGGTATTA TCCCGTATTG ACGCCGGGCA AGAGCAACTC GGTCGCCGCA TACACTATTC TCAGAATGAC TTGGTTGAGT ACTCACCAGT CACAGAAAAG CATCTTACGG ATGGCATGAC AGTAAGAGAA TTATGCAGTG CTGCCATAAC CATGAGTGAT AACACTGCGG CCAACTTACT TCTGACAACG ATCGGAGGAC CGAAGGAGCT AACCGCTTTT TTGCACAACA TGGGGGATCA TGTAACTCGC CTTGE100003, scramble sequence in pCas-Guide vector |
| Disclaimer | These products are manufactured and supplied by OriGene under license from ERS. The kit is designed based on the best knowledge of CRISPR technology. The system has been functionally validated for knocking-in the cassette downstream the native promoter. The efficiency of the knock-out varies due to the nature of the biology and the complexity of the experimental process. |
| Reference Data | |
| RefSeq | NM_001216 |
| UniProt ID | Q16790 |
| Synonyms | CAIX; MN |
| Summary | Carbonic anhydrases (CAs) are a large family of zinc metalloenzymes that catalyze the reversible hydration of carbon dioxide. They participate in a variety of biological processes, including respiration, calcification, acid-base balance, bone resorption, and the formation of aqueous humor, cerebrospinal fluid, saliva, and gastric acid. They show extensive diversity in tissue distribution and in their subcellular localization. CA IX is a transmembrane protein and is one of only two tumor-associated carbonic anhydrase isoenzymes known. It is expressed in all clear-cell renal cell carcinoma, but is not detected in normal kidney or most other normal tissues. It may be involved in cell proliferation and transformation. This gene was mapped to 17q21.2 by fluorescence in situ hybridization, however, radiation hybrid mapping localized it to 9p13-p12. [provided by RefSeq, Jun 2014] |
Documents
| Product Manuals |
| FAQs |
| SDS |
Resources
Other Versions
| SKU | Description | Size | Price |
|---|---|---|---|
| KN204839BN | CA9 - human gene knockout kit via CRISPR, HDR mediated |
USD 1,657.00 |
|
| KN204839LP | CA9 - human gene knockout kit via CRISPR, HDR mediated |
USD 1,657.00 |
|
| KN204839RB | CA9 - human gene knockout kit via CRISPR, HDR mediated |
USD 1,657.00 |
|
| KN404839 | CA9 - KN2.0, Human gene knockout kit via CRISPR, non-homology mediated. |
USD 1,657.00 |
|
| GA100535 | CA9 CRISPRa kit - CRISPR gene activation of human carbonic anhydrase 9 |
USD 1,657.00 |
{0} Product Review(s)
Be the first one to submit a review